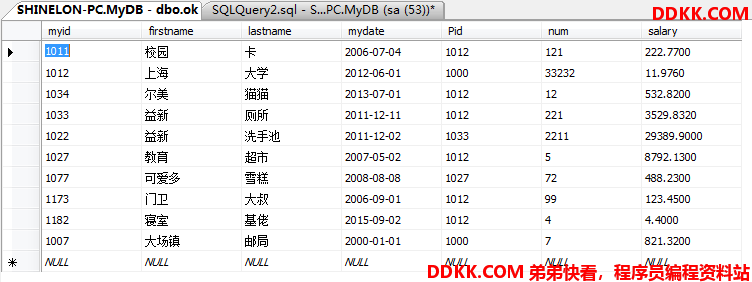
先创建一个新的用户数据库以后实验用:
CREATE DATABASE MyDB
ON
(
name=MY_dat1,
filename='E:\Source Program\CreatTest\Lzh_dat1.mdf',
size=10MB,
maxsize=30MB,
filegrowth=5MB
)
LOG ON
(
name=MY_log1,
filename='E:\Source Program\CreatTest\lzh_log1.ldf',
size=3MB,
maxsize=unlimited,
filegrowth=3MB
)
在里面建一张表:
USE MyDB; --在MyDB数据库下
IF OBJECT_ID('ok','U') IS NOT NULL --如果这个表已经存在
DROP TABLE ok; --删除表
CREATE TABLE ok --创建表
(
myid INT NOT NULL,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
mydate DATE NOT NULL,
Pid INT NULL,
num VARCHAR(20) NOT NULL,
salary MONEY NOT NULL --MONEY数据类型是2008及以后版本才有的
);
随便写几行:
SELECT语句包含子句时的语法
USE 数据库名;
SELECT 要返回的结果集列表
FROM 要查询的表名
WHERE 对整表数据过滤的条件
GROUP BY 分组依据列表
HAVING 对分组数据过滤的条件
ORDER BY 排序依据列表;
实际上,各子句逻辑上按如下顺序进行处理:
->FROM 找到表
->WHERE 过滤一次
->GROUP BY 分好组
->HAVING 对组过滤
->SELECT 查询得到结果集
->ORDER BY 对结果集排序
如果实际书写的查询逻辑效率不高也没关系,SQL Server并不严格按照这个逻辑来做查询,而是自由调整只要使得最终结果和这样的逻辑查询到的结果一致就行。
FROM子句
简单地指定要对哪些表进行查询。SQL Server解析架构名需要付出额外的开销,不妨在指定表时候显式指明架构名称。
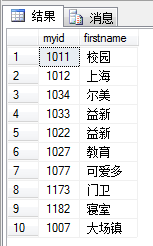
USE MyDB;
SELECT myid,firstname
FROM dbo.ok; --指明是在dbo架构下的ok表
WHERE子句
指定一个逻辑表达式,从而过滤由FROM阶段返回的行。
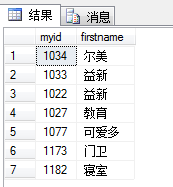
USE MyDB;
SELECT myid,firstname
FROM dbo.ok --指明是在dbo架构下的ok表
WHERE myid>1020; --只要其中myid>1020的行
GROUP BY子句
根据分组列表指定的唯一组合,为它们分成一个组。
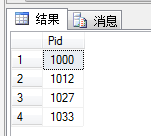
USE MyDB;
SELECT Pid
FROM dbo.ok --指明是在dbo架构下的ok表
GROUP BY Pid; --每个Pid的唯一组合(如果有别的列就和别的列组合)生成一个组
如果涉及到了分组,那么GROUP BY之后的所有阶段,包括HAVING、SELECT以及ORDER BY的操作对象将是组,而不是单独的行。也就是说GROUP BY之后处理的子句中指定的所有表达式必须每个组只返回一个单值,而不能像之前那样一行一个值了。
所以可以使用聚合函数,把组内的某列都聚合成一个单值,就可以放进SELECT里而即便GROUP BY里没有这列了:
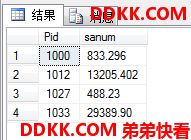
USE MyDB;
SELECT Pid,SUM(salary) AS sanum --用聚合函数把组内的所有salary加起来为sanum列
FROM dbo.ok --指明是在dbo架构下的ok表
GROUP BY Pid; --每个Pid的唯一组合(如果有别的列就和别的列组合)生成一个组
HAVING子句
WHERE阶段对单独的行过滤,而HAVING阶段对组进行过滤。
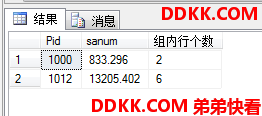
USE MyDB;
SELECT Pid,SUM(salary) AS sanum,COUNT(*) AS "组内行个数"
FROM dbo.ok --指明是在dbo架构下的ok表
GROUP BY Pid --每个Pid的唯一组合(如果有别的列就和别的列组合)生成一个组
HAVING COUNT(*)>1; --过滤掉那些组内只有一行的
SELECT子句
主要要记住SELECT虽然写在前面,但是也是在前面那些子句做完了才执行的,所以在SELECT阶段用AS定义的别名在那些子句里不能用是正常的,因为那个时候还没定义别名。而且在SELECT内部也不能使用SELECT阶段定义的别名,因为这句话还没说完别名没有生效。所以还是要写重复的表达式。
ORDER BY子句
在SELECT结束后已经有结果集了,这个子句就是对展示数据时输出结果中的行进行排序。ORDER BY是最后处理的一个子句。
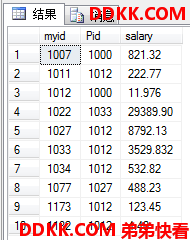
USE MyDB;
SELECT myid,Pid,salary
FROM dbo.ok --指明是在dbo架构下的ok表
ORDER BY myid; --对结果集根据myid排序输出
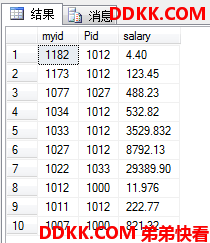
USE MyDB;
SELECT myid,Pid,salary
FROM dbo.ok --指明是在dbo架构下的ok表
ORDER BY myid DESC; --对结果集根据myid反向排序输出
TOP选项
TOP选项取结果集的前几行或者前百分之多少,虽然写在SELECT语句里,但是实际上是在ORDER BY做完以后再做的!
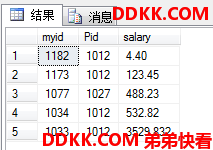
USE MyDB;
SELECT TOP (5) myid,Pid,salary --最后取前五行
FROM dbo.ok --指明是在dbo架构下的ok表
ORDER BY myid DESC; --对结果集根据myid反向排序输出
OVER子句
OVER子句用来对行定义一个窗口,这就像前面的分组一样,但是前面看到了分组以后,SELECT的要么是分组依据列,要么就是用聚合函数把组内的行聚合到一组去了。为了在返回基本列的同时又能进行聚合,就需要OVER子句了。
主要注意这三个用法:
①带有空括号的OVER()子句会提供在FROM、WHERE和GROUP BY以后仍然可用的所有行进行计算
②聚合函数 OVER(PARTITION BY 分窗依据列) AS 新列名
③排名函数 OVER(ORDER BY 排序依据列) AS 新列名
例如:
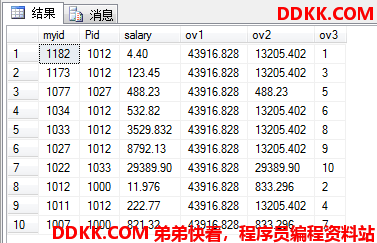
USE MyDB;
SELECT myid,Pid,salary,
SUM(salary) OVER() AS ov1, --所有可用行的salary加一起(聚合)
SUM(salary) OVER(PARTITION BY Pid) AS ov2, --根据Pid分窗再聚合
RANK() OVER(ORDER BY salary) AS ov3 --所有可用行根据salary用RANK()排序
FROM dbo.ok
ORDER BY myid DESC;
关于OVER子句更详细的在我的笔记10。
DISTINCT选项
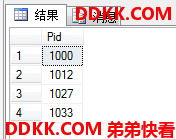
就是结果集里重复的行只保留一个。
USE MyDB;
SELECT DISTINCT Pid
FROM dbo.ok;
逻辑处理顺序总结
-
FROM
-
WHERE
-
GROUP BY
-
HAVING
-
SELECT
-
OVER
-
DISTINCT
-
TOP
-
ORDER BY