1. 什么是JVM 的内存区域划分
JVM在运行写好的代码时,必须使用多块内存空间,不同的内存空间用来放不同的数据,然后配合写的代码流程,才能让系统运行起来。
JVM里必须有一块内存区域,用来存放写的那些类;其次,在运行方法的时候,方法里的很多变量,也需要放在内存区域里;再有就是,写的代码里创建一些对象,他们也需要内存空间来存放。
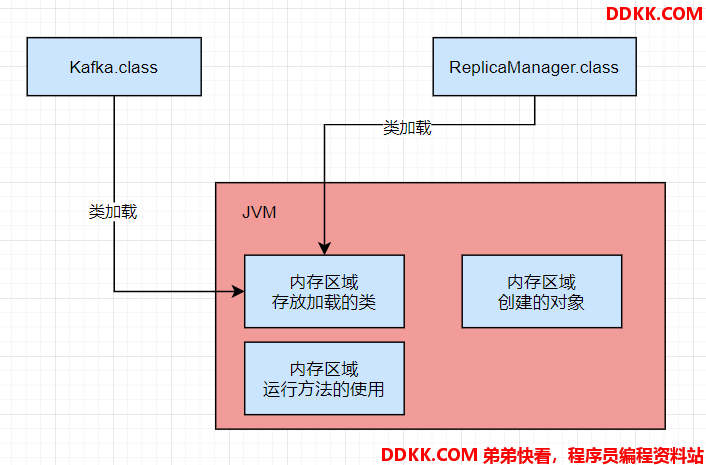
以上,就是JVM必须划分不同的内存区域的原因。
2. 存放类的方法区
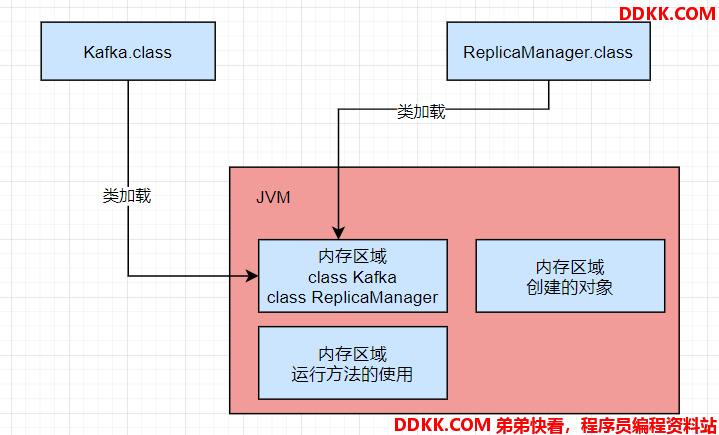
JDK1.8以前的版本里,方法去代表JVM中的一块区域。主要是放从 “.class” 文件里加载进来的类,还会有一些类似常量池的东西放在这个区域里。。
JDK1.8以后的版本里,这块区域的名字改为 “Metaspace” ,又称 “元数据空间” 。主要还是存放自己写的各种类相关的信息。
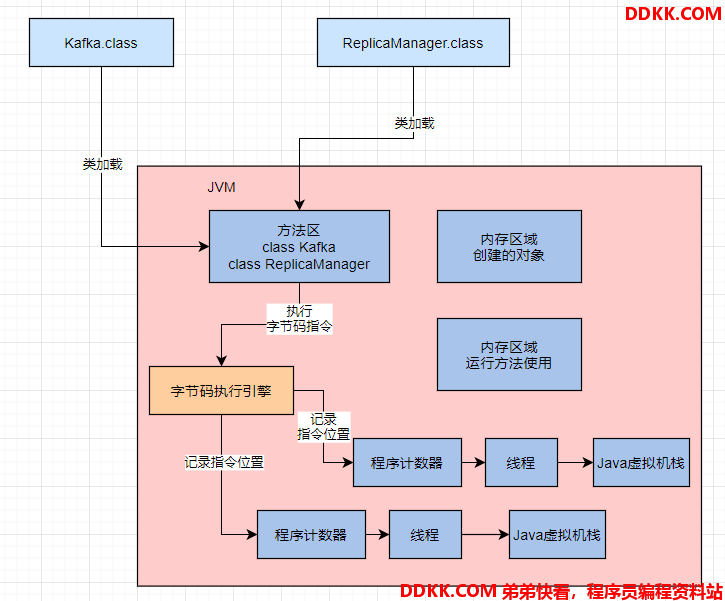
前面的kafka.class 示例在加载到 JVM后的方法区图示:
3.执行代码指令用的程序计数器
1、 字节码
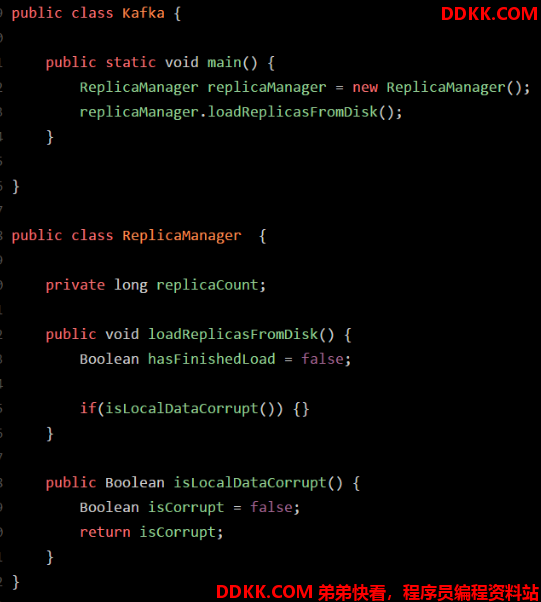
如下示例代码:
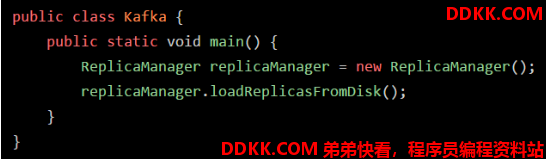
上述代码先编写于 “.java” 后缀的源代码文件里,经过编译器编译后,被编译为 “.class” 后缀的字节码文件。
在“.class” 后缀的字节码文件里,存放的就是代码编译好的字节码了。字节码才是计算机可以理解的一种语言。
字节码大概如下格式:
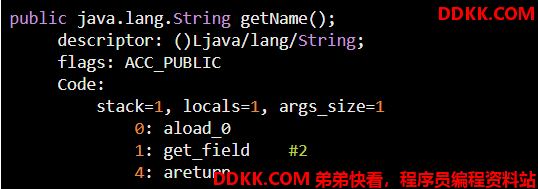
如上示例,“0:aload_0” 这样的,就是 “字节码指令” ,它对应一条条的机器指令,计算机只有读到这种机器的指令,才知道具体应该要干什么。
总之,我们写好的Java代码会被翻译成字节码,对应各种字节码指令。Java代码也正是在被编译成字节码指令之后,再一条一条去执行字节码指令,从而实现代码的执行效果。
2、 字节码执行引擎
所以当JVM加载类信息到内存之后,实际就会使用自己的字节码执行引擎,去执行写好的代码编译出来的代码指令,如下图:
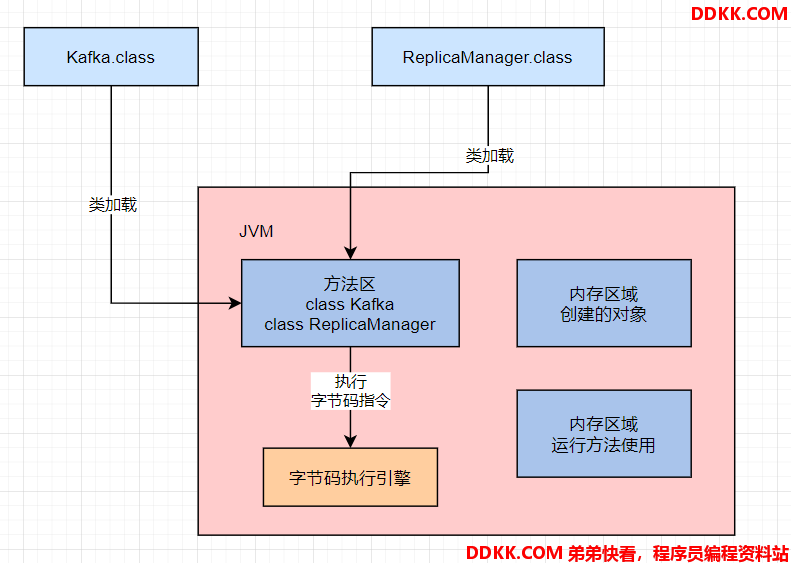
3、 程序计数器
在执行字节码指令的时候,JVM里需要一个特殊的内存区域,也就是 “程序计数器”。它用来记录当前执行的字节码指令的位置,即记录目前执行到了哪一条字节码指令。
如下图:
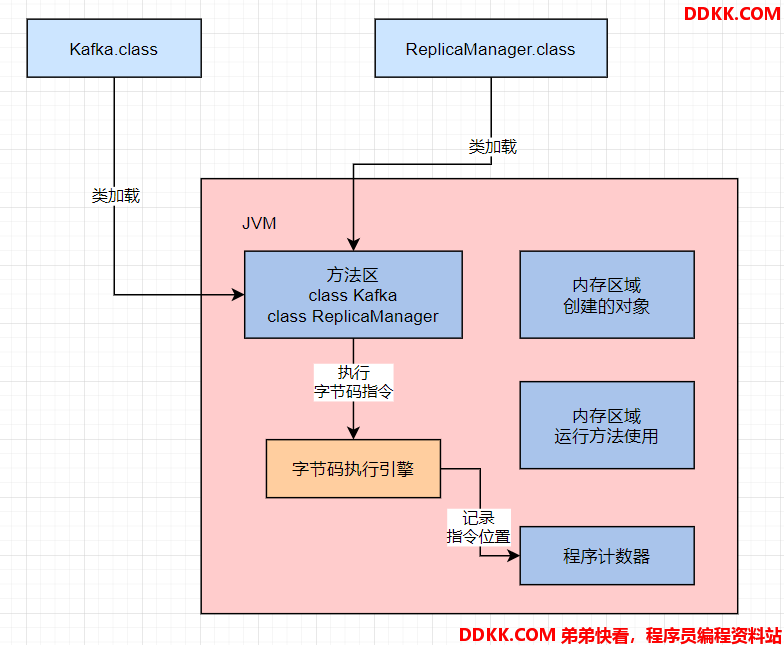
JVM是支持多线程的,因此每个线程都会有自己的一个程序计数器,专门记录当前这个线程目前执行到了哪一条字节码指令。
如下图:
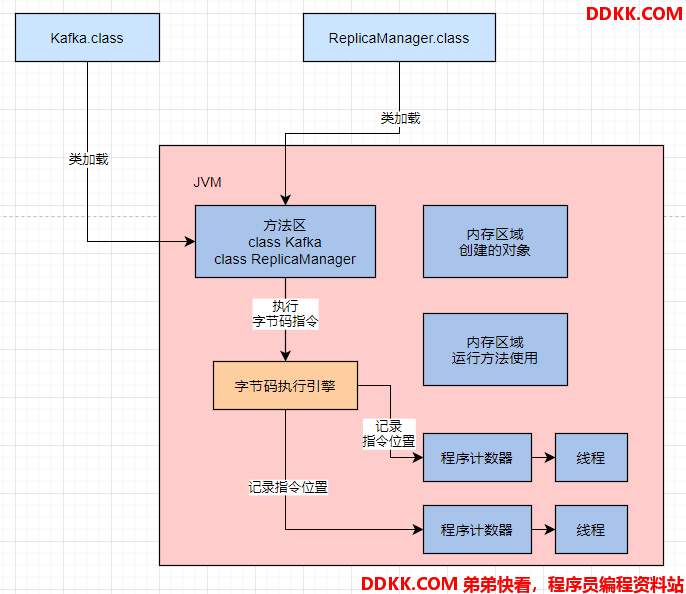
4. Java虚拟机栈
Java代码在执行的时候,是线程来执行某个方法中的代码。
比如:在 main 线程执行 main() 方法的代码指令的时候,就会通过 main 线程对应的程序计数器记录自己执行的指令位置。
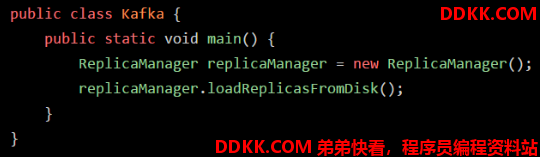
在上述代码示例中,在 main() 方法里,定义有 “replicaManager” 局部变量,该变量引用一个 ReplicaManager 实例对象。
在JVM中,必须有一块区域是来保存每个方法内的局部变量等数据的,这个区域就是 Java 虚拟机栈。
每个线程都有自己的 Java 虚拟机栈。
如果线程执行了一个方法,就会对这个方法调用创建对应的一个栈帧。栈帧里有这个方法的局部变量表、操作数栈、动态链接、方法出口等。
在上述示例中, main线程执行了main()方法,就会给 main() 方法创建一个栈帧,压入 main 线程的 Java 虚拟机栈。同时在 main() 方法的栈帧里,会存放对应的 “replicaManager” 局部变量。

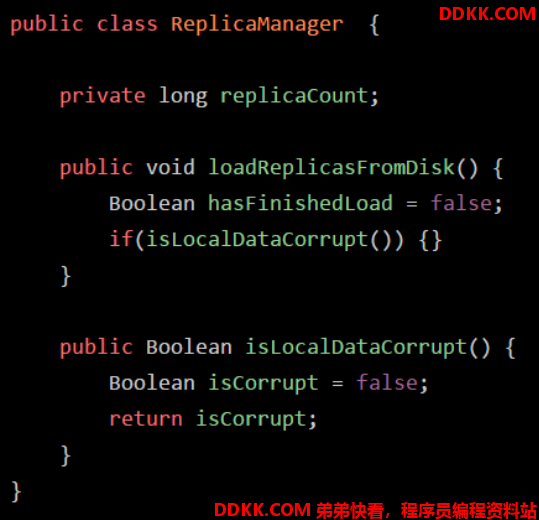
假设在main() 方法的 ReplicaManager 对象里的 loadReplicasFromDisk() 方法中,也定义了一个局部变量:“hasFishedLoad”
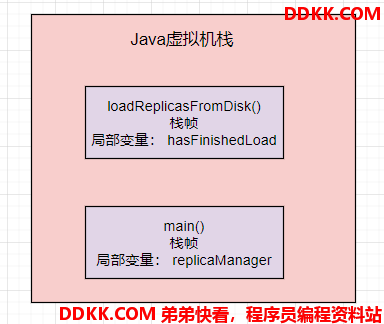
那么main线程在执行 “loadReplicasFromDisk” 方法时,也会为该方法创建一个栈帧压入线程自己的 Java 虚拟机栈里面去。
然后在栈帧的局部变量表里就会有 “hasFinishedLoad” 这个局部变量。如下图:
如果“loadReplicasFromDisk” 方法调用了另一个 “isLocalDataCorrupt()” 方法,这个方法里也有自己的局部变量 “isCorrupt”。
这时就会给 “isLocalDataCorrupt()” 方法创建一个栈帧,压入线程的 Java 虚拟机栈里。
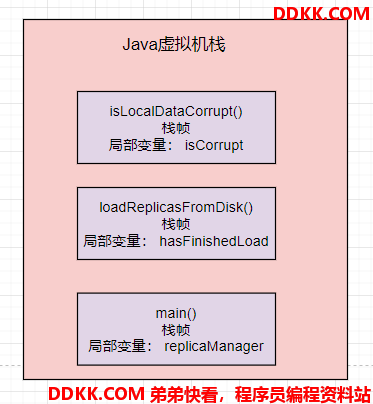
接着如果 “isLocalDataCorrupt” 方法执行完毕了,就会把 “isLocalDataCorrupt” 方法对应的栈帧从 Java虚拟机栈里给出栈。
然后如果 “loadReplicasFromDisk” 方法也执行完毕了,就会把 “loadReplicasFromDisk” 方法也从 Java 虚拟机栈里出栈。
**Java虚拟机栈的作用:**调用执行任何方法时,都会给方法创建栈帧然后入栈。在栈帧里存放了这个方法对应的局部变量之类的数据,包括这个方法执行的其他相关的信息,方法执行完毕之后就出栈。
5.Java 堆内存
JVM中的另一个区域,Java堆内存。用于存放在代码中创建的各种对象的。
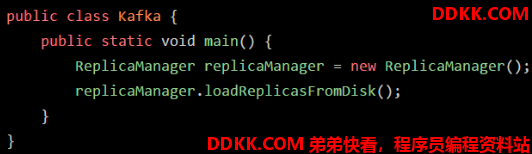
“new ReplicaManager()” 这个代码创建了一个 ReplicaManager 类的对象实例,在对象实例里面会包含一些数据(比如:“replicaCount”)。
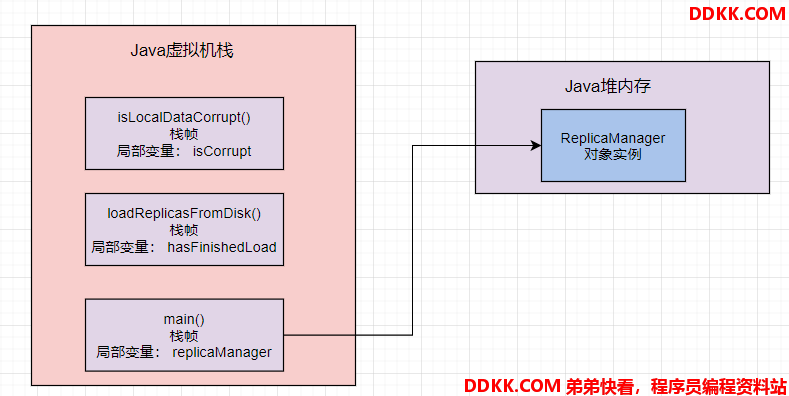
类似ReplicaManager 这样的对象实例,会存放在 Java 堆内存里。如下:
Java 堆内存区域里会放入类似 ReplicaManager 的对象,因为在 main 方法里创建 ReplicaManager 对象的,那么在线程执行 main 方法代码的时候,就会在 main 方法对应的栈帧的局部变量表里,让一个引用类型的 “replicaManager” 局部变量来存放 ReplicaManager 对象的地址。
相当于局部变量表里的 “replicaManager” 指向了 Java 堆内存里的 ReplicaManager 对象。
6. 核心内存区域的全流程串讲
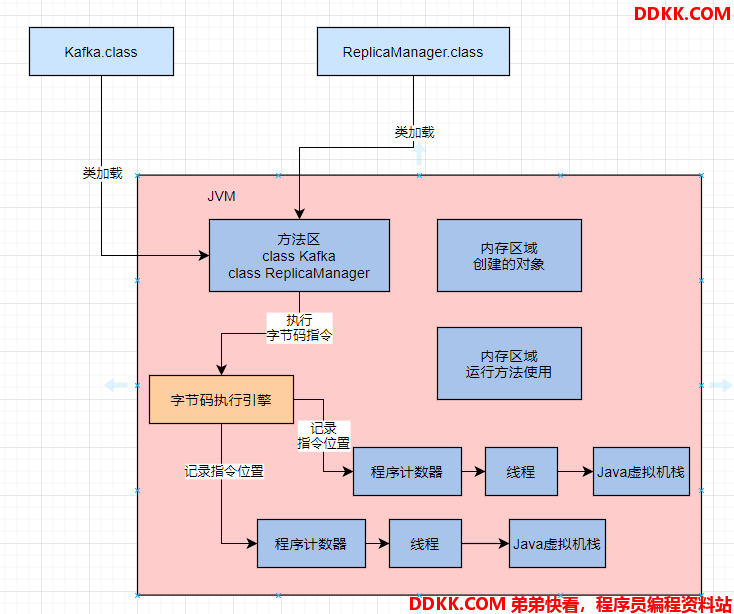
首先,JVM进程启动,就会先加载 Kafka类到内存里,然后有一个 main 线程,开始执行 Kafka 中的 main() 方法。
main 线程关联了一个程序计数器,它执行到哪一行指令,就会记录在这里。
结合程序计数器理解,就是 main 线程在执行 main() 方法的时候,会在 main 线程关联的 Java 虚拟机栈里,压入一个 main() 方法的栈帧。
接着会发现需要创建一个 ReplicaManager 类的实例对象,此时会加载 ReplicaManager 类到内存里来。
然后会创建一个 ReplicaManager 的对象实例分配在 Java 堆内存里,并且在main() 方法的栈帧里的局部变量表引入一个 “replicaManager” 变量,让它引用 ReplicaManager 对象在 Java 堆内存中的地址。
接着,main 线程开始执行 ReplicaManager 对象中的方法,会一次把自己执行到的方法对应的栈帧压入自己的 Java 虚拟机栈。
执行完方法之后再把方法对应的栈帧从 Java虚拟机栈里出栈。
7. 其他内存区域
在JDK 很多底层 API里,比如 IO相关的, NIO相关的,等等。他们的内部源码,很多地方并不是 Java 代码,而是走的 native 方法去调用本地操作系统里面的一些方法。
在调用这种 native 方法的时候,会有线程对应的本地方法栈,这个里面也是跟Java虚拟机栈类似,也是存放各种 native 方法的局部变量之类的信息。
还有一个区域,是不属于 JVM的,通过 NIO中的 allocateDirect 这种 API,可以在 Java 堆外分配内存空间。然后,通过 Java 虚拟机里的 DirectByteBuffer 来引用和操作堆外内存空间。
8. 思考题
Tomcat 这种 Web 容器中的类加载器应该如何设计实现?
首先Tomcat 的类加载器体现如下图所示,它是自定义了很多类加载器的。
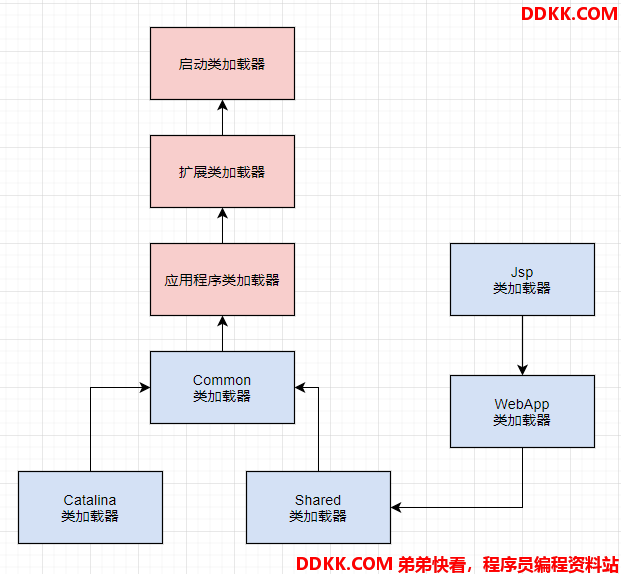
Tomcat自定义了 Common、Catalina、Shared等类加载器,他们是用来加载 Tomcat自己的一些核心基础类库的。
然后Tomcat为每个部署在里面的 Web 应用都有一个对应的 WebApp 类加载器,负责加载我们部署的这个 Web 应用的类。
至于Jsp 类加载器,则是给每个 JSP 都准备了一个 Jsp 类加载器。
Tomcat 是打破了双亲委派机制的。每个 WebApp 复制加载自己对应的那个 Web 应用的 class 文件,也就是我们写好的某个系统打包好的 war 包中的所有 class 文件,不会传导给上层类加载器去加载。